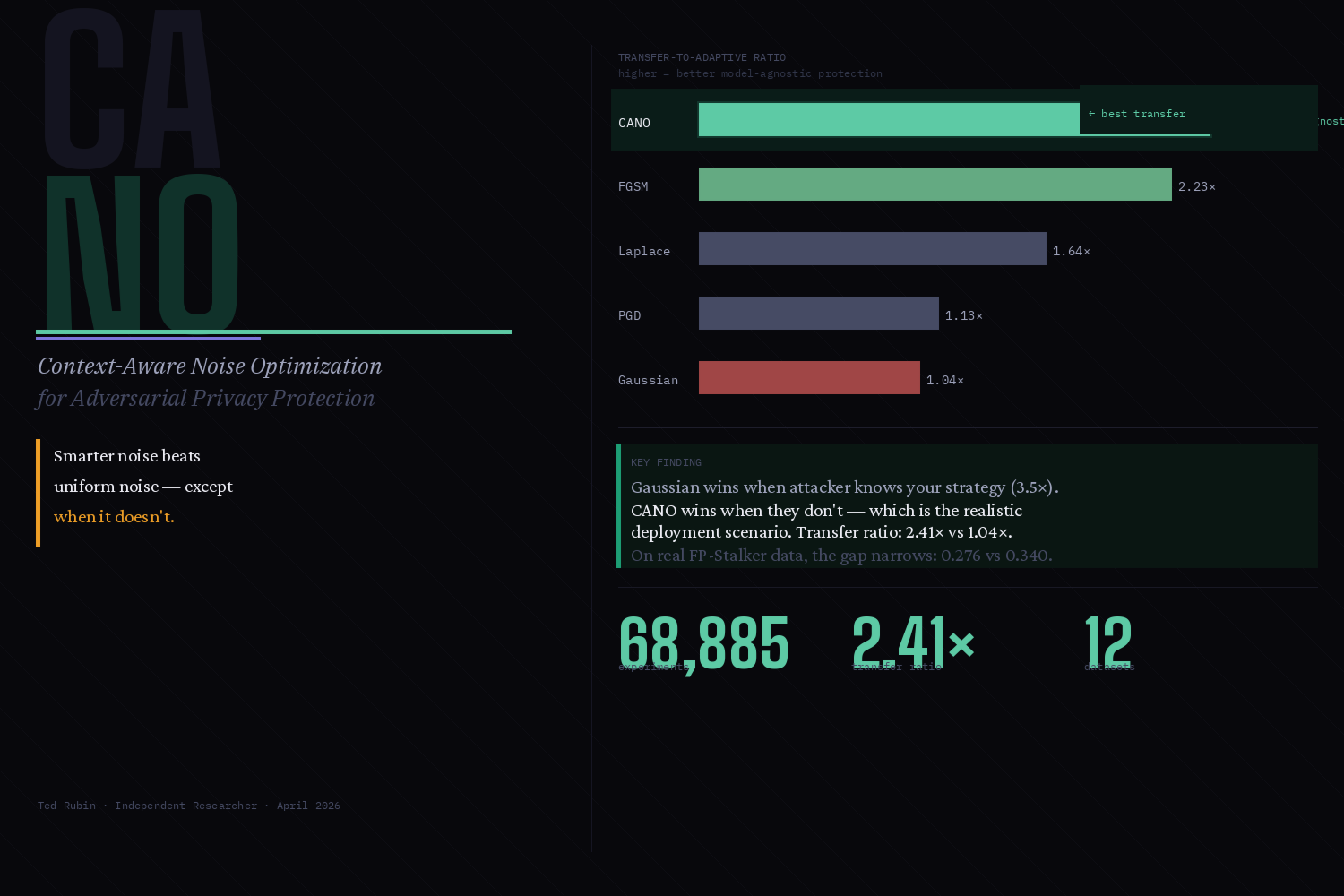
I Fine-Tuned an 8B Model to Stop Being Agreeable. It Runs on a Single CPU for $0/Month
I Fine-Tuned an 8B Model to Stop Being Agreeable. It Runs on a Single CPU for $0/Month. Carole is a chatbot built for neurodivergent users — specifically those with rejection-sensitive dysphoria. She validates first, then redirects. Not “great idea, here’s why you’re wrong.” Actual validation. Then a question that reframes the problem. The whole stack — fine-tune, RAG, inference, gated web demo — cost under $20 to build and nothing to run.